The search engine Google is still the market leader for online search.
Worldwide it’s at about 92% market share, which falls a little to 90% in the UK in August 2017 (See http://gs.statcounter.com/search-engine-market-share/all/united-kingdom/#monthly-201608-201708 ).
While Microsoft’s Bing is a credible search engine, it is still only used by 6% of users.

What Googlebot does
Therefore it is important to understand how Google finds out about websites and that’s through and its spider Googlebot. This is a special computer program that visits websites and gathers information about them.
In fact it could be crawling your website right now retrieving information about your content. Once it gathers information from across hundreds of billions of webpages and it then organizes it in the Google search index.
How Googlebot gathers information about websites
The crawling process begins with a list of web addresses from past crawls and sitemaps provided by website owners.
As Googlebot visit these websites, it uses links on those sites to discover other pages. The software pays special attention to new sites, changes to existing sites and dead links.
The Google system determines which sites to crawl, how often and how many pages to fetch from each site.
When Googlebot finds a webpage, the systems render the content of the page, just as a browser does. It notes key signals — from keywords to website freshness — and keeps track of it all in the Search index.
The Google Search index contains hundreds of billions of webpages and is well over 100,000,000 gigabytes in size. It’s like the index in the back of a book — with an entry for every word seen on every web page they index. When they index a web page, it’s added to entries for all of the words it contains.
For most sites, Googlebot shouldn’t access your site more than once every few seconds on average. However, due to network delays, it’s possible that the rate will appear to be slightly higher over short periods.
Using Google search console to check your site is being indexed
While Googlebot chooses when and how often it visits your website it is possible to influence what it sees (and in some cases stop it from indexing parts or all of your website).
Google provides a free tool called Google Search Console (https://www.google.com/webmasters/tools/home?hl=en) which provides lots of very useful information on how your website is being indexed by Google plus warnings on issues such as the presence of malware, other security issues and even using old versions of your Content Management System.
Google Search console is particularly useful for the following:
- Using the robots.txt file you can encourage or discourage Googlebot to index certain pages or folders on your website. Use it with care and test it to make sure Googlebot can access your site.
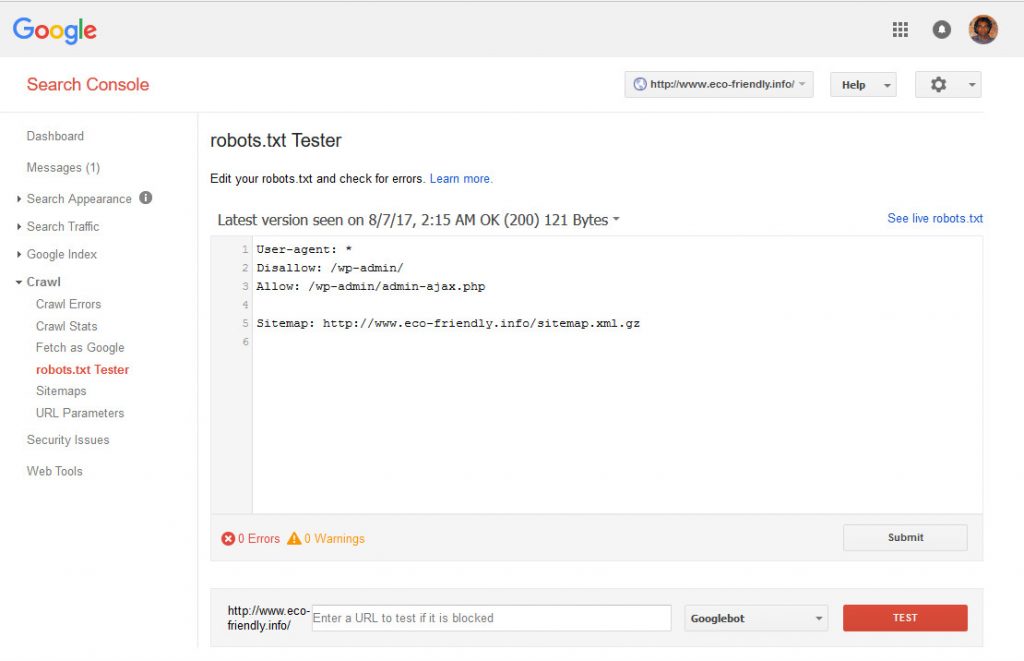
- Check the section on Crawl errors for broken links and fix on your site or tell Google to disregard them if the page is ok.
- The Fetch as Google tool in Search Console helps you understand exactly how your site appears to Googlebot. This can be very useful when troubleshooting problems with your site’s content or discoverability in search results.
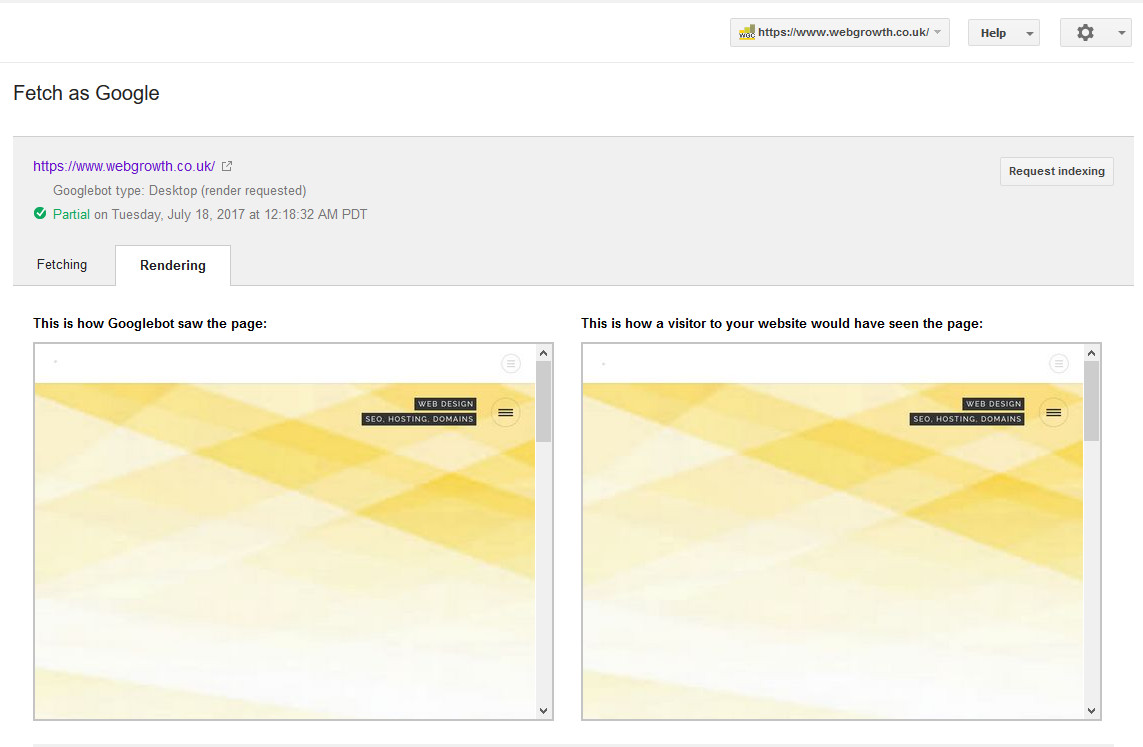

Although Google’s human software engineer configure and adjust Googlebot continuously, once it sets off to index websites there is very little human intervention after that. It’s an automated process that pays little attention to pretty graphics or stunning web designs.
It blindly downloads the text from your web page content, meta tags and key signals and stores them in the Google search index.
See our earlier blog posts on Google Search console which describes how to ask Google to index your website. Also check our blog pots on ranking signals – Google ranking signals.
Useful links
https://support.google.com/webmasters/answer/182072?hl=en
https://www.google.com/search/howsearchworks/